Beyond Seeing and Hearing: Meta's New AI Model Unifies Sensory Perception in a Single Brain
Translate this article
For humans, perception is a symphony. The crunch of leaves underfoot confirms what our eyes see. The distant siren warns us to check the mirror before we see the ambulance. Our brains don’t process sight, sound, and language in isolation; they weave them together into a coherent understanding of the world. For AI, however, this integration has remained a stubborn challenge. Models that excel at vision often stumble on audio, and audio specialists can be blind to context.
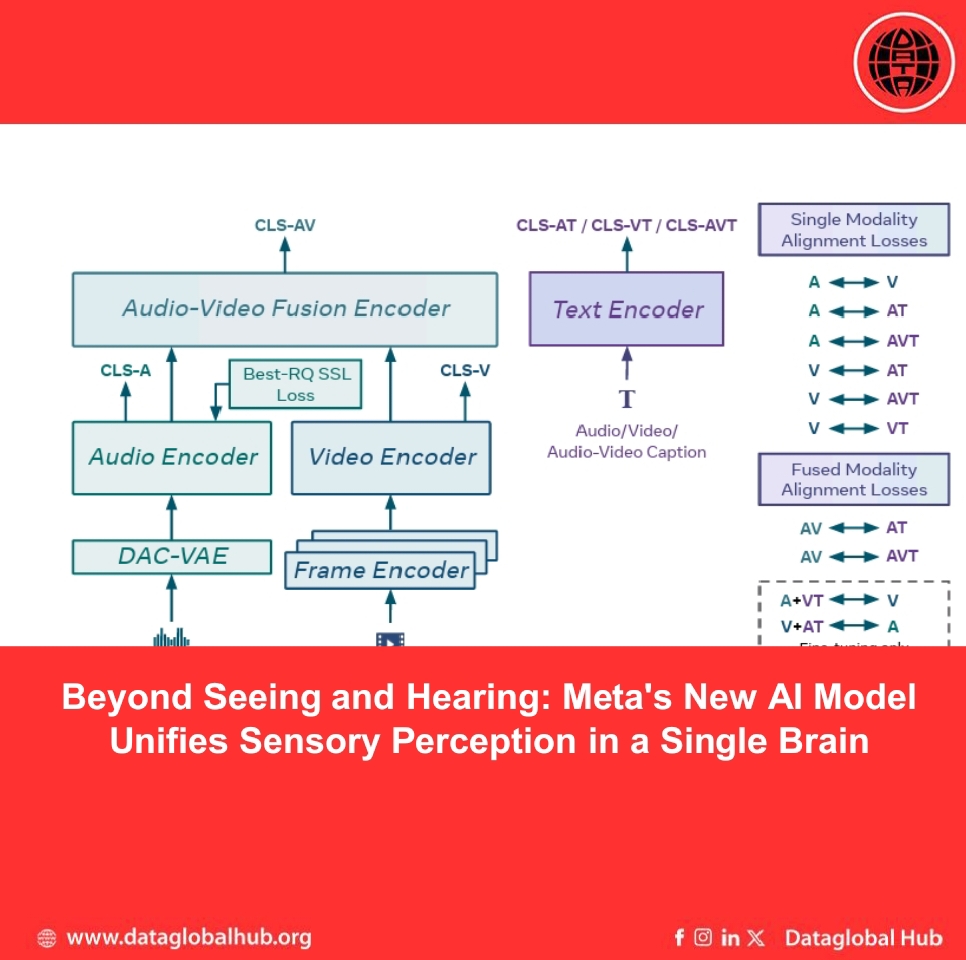
Researchers from Meta’s Superintelligence Labs are unveiling a significant step toward closing this gap. They’ve introduced Perception Encoder Audiovisual (PE-AV), a new family of AI models designed to natively understand and link audio, video, and text within a single, unified system. This isn't just another incremental benchmark-topper; it's a foundational rethinking of how to build a machine that perceives the world more like we do.
The research, detailed in a new paper, tackles a core weakness of previous "hub-style" multimodal models. Approaches like ImageBind (which anchors everything to images) or LanguageBind (which anchors everything to text) struggle when their anchoring modality is missing or weak. Ask an image-anchored model to find a sound based on a text description alone, and it falters.
PE-AV’s breakthrough rests on two pillars: scale and synergy.
First, the team built a massive, two-stage "audiovisual data engine" to solve a critical data shortage. High-quality, aligned audio-video-text data is scarce. Their solution was to generate it synthetically at an unprecedented scale—roughly 100 million clips. They started by using a large language model (Llama 3.1) to intelligently combine outputs from weaker audio-captioning tools with video captions, creating an initial training set. They then used an early version of PE-AV itself to refine these captions further, resulting in a corpus of remarkably high-quality and diverse descriptions for sound, visuals, and their combination.
Second, they scaled the learning objective itself. Instead of training on just one or two relationships (like audio-to-text), PE-AV is trained using ten distinct contrastive objectives that explore every possible alignment between audio, video, and different caption types. This forces the model to build a robust, interconnected embedding space where a concept like "ambulance" is linked equally well to its image, its siren, and the word describing it.
The results are commanding. PE-AV sets new state-of-the-art marks across a wide spectrum of zero-shot benchmarks, meaning it generalizes to tasks it was never explicitly trained for. Key achievements include:
· Audio Retrieval: Text-to-audio retrieval on the AudioCaps benchmark jumped from a previous best of 35.4% to 45.8%.
· Speech Understanding: Perhaps most striking is its capability in speech-to-transcript retrieval, a task where previous models essentially failed (near 0% success). PE-AV achieves 85.6% accuracy, demonstrating a nuanced understanding of spoken language.
· Video Understanding: It also pushes the frontier in video tasks, improving text-to-video retrieval on ActivityNet and classification on Kinetics-400, even surpassing models with 2-4 times more parameters.
· Unified Queries: The model can answer complex cross-modal queries. For example, it can find the right piece of music for a video using a text description of the desired mood (e.g., "retrieve upbeat electronic music for this sunset driving clip").
The team also introduced a specialized variant, PEₐ‑Frame, fine-tuned for frame-level alignment. This model excels at Sound Event Detection (SED), pinpointing not just what sounds occur in a complex audio mix, but exactly when. It achieves top results on both open-vocabulary (finding sounds described in free-form text) and closed-vocabulary benchmarks.
Meta is releasing the models and code openly, positioning PE-AV as a foundational tool for the community. The implications are broad: more intuitive multimedia search, powerful assistive tools for the hearing or visually impaired, advanced content moderation systems that understand context, and a stronger perceptual backbone for the next generation of AI assistants and robots.
The research affirms a powerful thesis: in the quest for machine intelligence, unifying the senses isn't just an optional feature—it's the pathway to deeper, more human-like understanding. By building a model that can truly listen, watch, and read all at once, Meta isn't just chasing benchmarks; it's teaching AI to perceive the chorus of the world, not just its isolated notes.
About the Author

Leo Silva
Leo Silva is an Air correspondent from Brazil.
Recent Articles
Subscribe to Newsletter
Enter your email address to register to our newsletter subscription!