Beyond Whisper: How Voxtral Is Redefining Open-Source Speech Intelligence
Translate this article
Voice is often called the original user interface. Before keyboards, screens, and code, speech was how humans coordinated, collaborated, and connected. As digital systems evolve, voice is once again becoming central as a key interface for machines. Yet despite decades of research and commercial investment, many voice-based systems remain either limited in capability or locked behind proprietary walls.
Voxtral: A New Open-Source Offering in Speech Understanding
Mistral AI introduces Voxtral a set of open-source speech understanding models built to address a long-standing gap in the voice technology space, built with high accuracy, broad language support, semantic understanding, and flexible deployment all without the constraints of closed systems.
Available in two sizes 1) 24B parameter model for large-scale deployment 2) 3B variant suited for local or edge use Voxtral models are released under the Apache 2.0 license. They are also available via API for developers looking to integrate voice capabilities directly into applications with minimal setup.
Why Voxtral Matters
Traditionally, organizations have had to choose between:
Voxtral offers a middle ground. It delivers strong transcription and speech understanding performance across multiple languages while remaining open, affordable, and production-ready. Pricing starts at $0.001 per minute via API, making it viable for both large-scale applications and budget-sensitive projects.
Key Features
Performance and Benchmarks
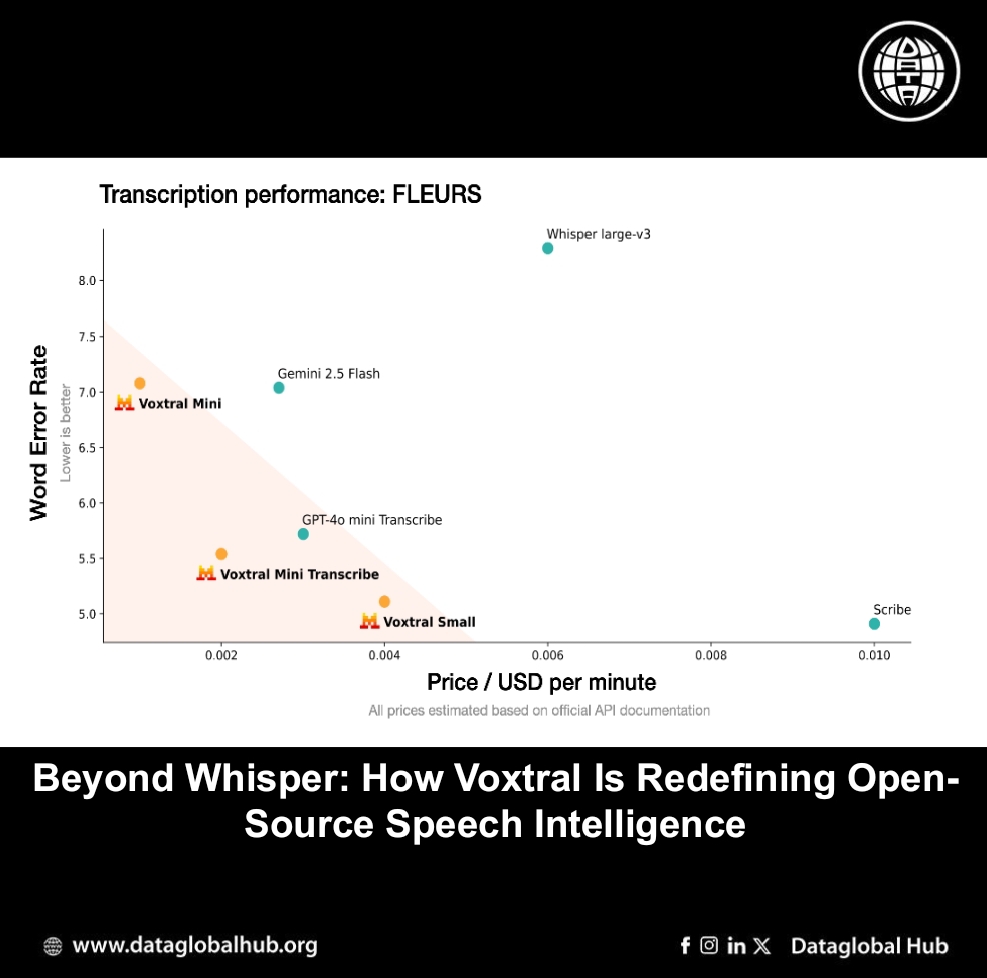
Transcription: Voxtral achieves state-of-the-art transcription accuracy, surpassing Whisper large-v3 and other open models on reported benchmarks, particularly in English short- and long-form datasets, as well as multilingual tasks like Mozilla Common Voice and FLEURS.
Voxtral offers a compelling option for developers, researchers, and organizations seeking open, accurate, and adaptable speech understanding tools. Without the restrictions of closed APIs or the limitations of traditional ASR models, Voxtral makes high-quality voice intelligence accessible to a much wider community.
About the Author

Chinedu Chimamora
Recent Articles
Subscribe to Newsletter
Enter your email address to register to our newsletter subscription!