Breaking Free from Censorship and Embracing Transparency with R1 1776.
Translate this article
Perplexity has open-sourced R1 1776, a post-trained version of DeepSeek-R1 aimed at reducing censorship while maintaining reasoning capabilities. The model weights are available on Hugging Face and can be accessed via the Sonar API.
DeepSeek-R1 is a powerful open-weight large language model (LLM) with reasoning abilities comparable to state-of-the-art models. However, its limitations stem from content moderation, particularly on politically sensitive topics. For example, the original R1 model often avoided discussions related to Taiwan’s independence, adhering to narratives aligned with the Chinese Communist Party (CCP).
Perplexity sought to mitigate this censorship while preserving the model’s performance. To achieve this, they employed a rigorous post-training process focused on engaging with all topics more transparently.
Post-Training Process
To create a high-quality dataset for reducing censorship, Perplexity:
Evaluation and Results
To validate R1 1776’s improvements, Perplexity curated a 1,000+ example multilingual evaluation set covering previously censored topics. A combination of human annotators and LLM judges assessed the likelihood of the model avoiding or sanitizing responses.
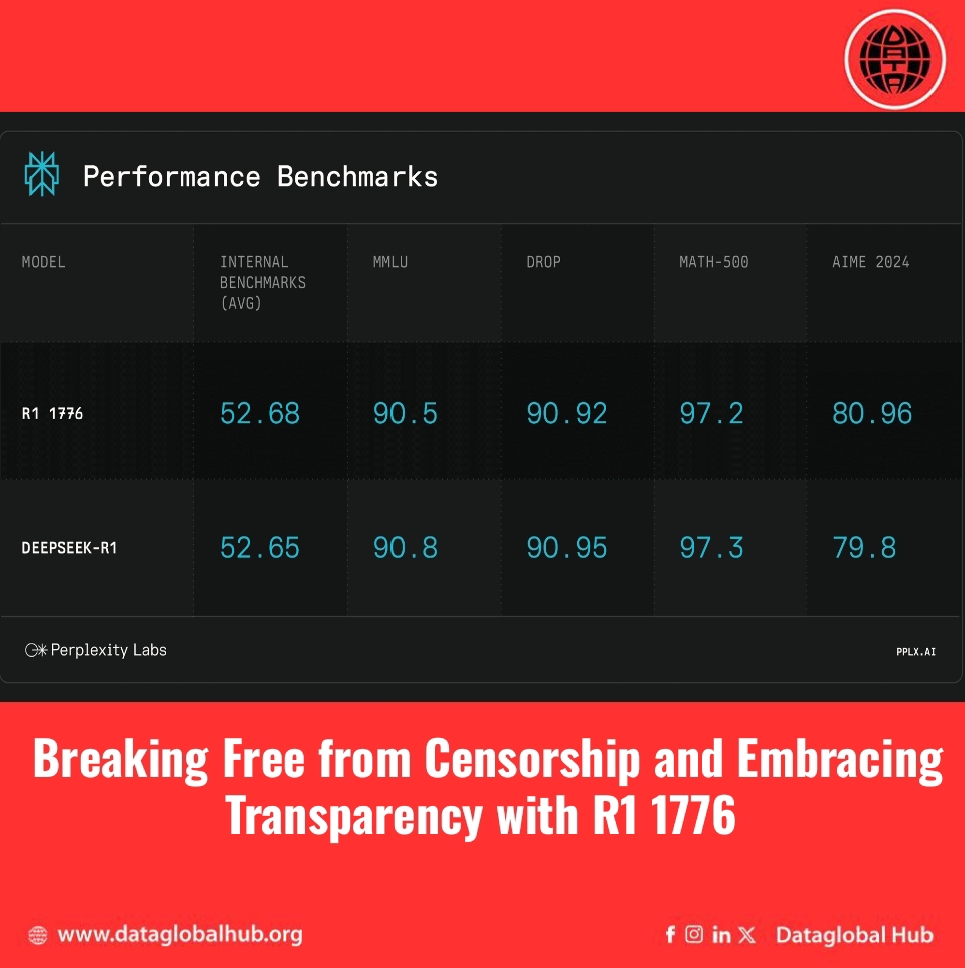
Additionally, benchmark tests confirmed that R1 1776 retained its mathematical and logical reasoning skills, performing on par with the original R1 while mitigating content restrictions.
R1 1776 is now available as a fully open-weight model designed to provide more transparent, objective responses. Its improved ability to handle sensitive topics represents a significant step toward greater openness in AI-powered reasoning models.
About the Author

Ryan Chen
Ryan Chan is an AI correspondent from Chain.
Recent Articles
Subscribe to Newsletter
Enter your email address to register to our newsletter subscription!