How to Teach an AI New Tricks Without It Forgetting the Old Ones
Translate this article
The quest to build AI that can learn continuously—much like a human accumulates knowledge and skills over a lifetime—has long been hampered by a frustrating flaw: catastrophic forgetting. When traditional methods train a model on a new task, its performance on previously learned tasks often plummets. A new research paper from MIT and ETH Zurich introduces a surprisingly elegant solution to this problem, enabling models to learn sequentially from demonstrations without degrading their existing capabilities.
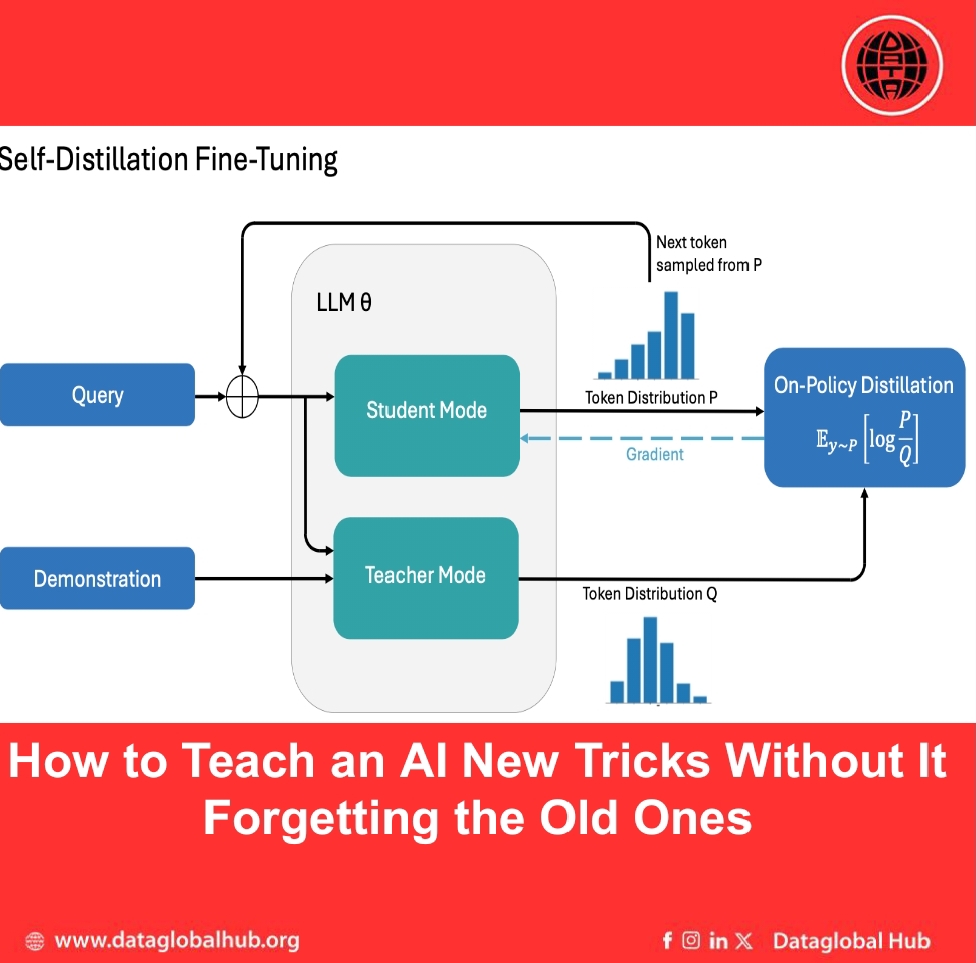
The method, called Self-Distillation Fine-Tuning (SDFT), tackles a core limitation of the standard approach, Supervised Fine-Tuning (SFT). While SFT learns from expert demonstrations, it does so "off-policy," meaning it only sees the perfect, expert-provided examples. This creates a mismatch: when the model makes a small error during actual use, it can veer into uncharted territory and fail, because it was never trained to recover from its own mistakes.
SDFT flips the script by enabling "on-policy" learning directly from demonstrations. It cleverly uses the model against itself in a self-improvement loop. The model, conditioned on an expert demonstration, generates its own attempt at the task. This attempt, which includes the model's natural errors and explorations, then becomes the training data. In essence, the model acts as its own teacher, learning to correct its own trajectories rather than just memorizing perfect ones.
The Results: Learning Without Forgetting
The experiments demonstrate a clear breakthrough. In a challenging sequential learning test where a single model was trained on three different tasks one after another, SDFT successfully learned each new skill while maintaining high performance on the previous ones. In stark contrast, the standard SFT method caused severe interference—the model's ability on earlier tasks rapidly deteriorated as soon as training shifted to something new.
Furthermore, SDFT didn't just prevent forgetting; it led to better learning. Across multiple skill-learning and knowledge-acquisition tasks, models trained with SDFT consistently achieved higher accuracy on new tasks than those trained with SFT. The reason is foundational: by training on its own generated paths, the model learns robustness and how to recover from errors, leading to stronger generalization.
A Method That Grows with the Model
Perhaps most promising is the scaling trend. The effectiveness of SDFT is directly tied to a model's inherent "in-context learning" ability—its skill at learning from examples provided within a prompt. At a smaller 3B parameter size, this ability was too weak for SDFT to be effective. However, as model scale increased, so did SDFT's advantage. The 7B model showed a 4-point improvement over SFT, and the 14B model widened the gap to 7 points. This suggests that as foundation models grow more capable, techniques like SDFT will become increasingly powerful for continual, cumulative learning.
By providing a practical path for on-policy learning from demonstrations, SDFT represents a significant step toward AI that can truly accumulate knowledge over time, paving the way for more adaptable and resilient intelligent systems.
The paper, "Self-Distillation Enables Continual Learning," is available on arXiv, and code has been open-sourced on GitHub.
Paper: https://arxiv.org/abs/2601.19897
About the Author

Aremi Olu
Aremi Olu is an AI news correspondent from Nigeria.
Recent Articles
Subscribe to Newsletter
Enter your email address to register to our newsletter subscription!