Kidney Transplants Get a Digital Ally in Predicting Graft Failure
Translate this article
In kidney transplantation, early identification of graft loss is essential for effective patient management. Yet this task is complicated by the inconsistent use of diagnostic codes in electronic medical records (EMRs). A recent study published in PLOS ONE introduces a promising approach using Natural Language Processing (NLP) and machine learning (ML) to classify kidney allograft status from unstructured EMR text—written entirely in Spanish.
The Problem:
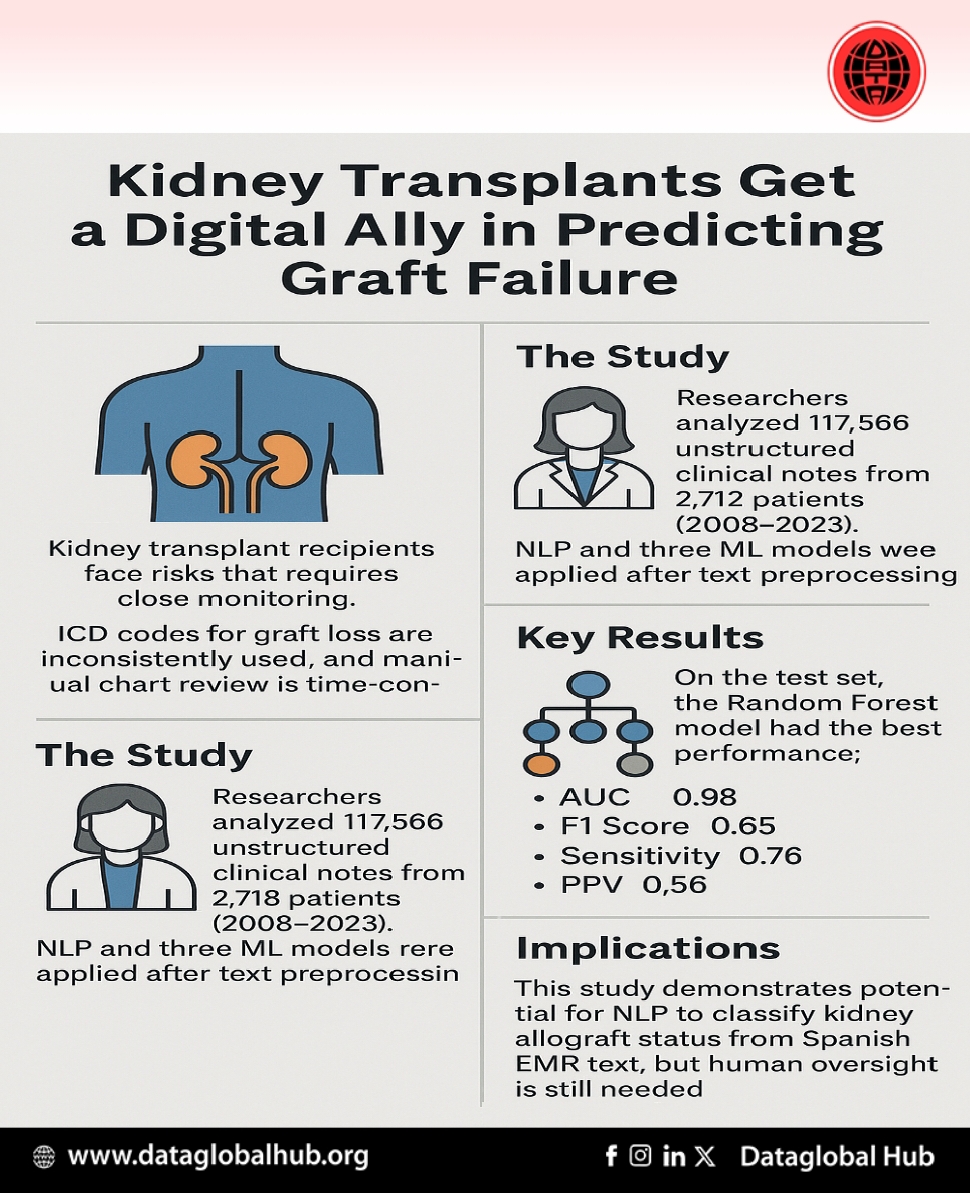
Kidney transplant recipients face risks that require close monitoring. While the International Classification of Diseases (ICD) includes codes for graft loss, their inconsistent use and lack of specificity hinder reliable tracking. Manual chart reviews remain the gold standard but are time-consuming and resource-intensive.
The Study:
Researchers led by Dr. Andrea Garcia-Lopez analyzed 117,566 unstructured clinical notes from 2,712 transplant patients treated at Colombiana de Trasplantes between 2008 and 2023. These notes included outpatient and discharge summaries—critical sources often overlooked by automated systems due to their free-text nature.
To address this, the team applied NLP techniques such as text normalization, stopword removal, spell-checking, and stemming. After transforming the data into a structured format using document-term matrices, they trained three ML models—Logistic Regression, Random Forest, and Neural Networks—using 10-fold cross-validation on a balanced dataset. Feature selection was performed using LASSO regression.
Key Results:
On the test set (which remained imbalanced to reflect real-world data), the Random Forest model achieved the highest overall performance:
While the results are promising, especially compared to traditional methods, the models still generated a notable number of false positives. This means additional manual validation is required before the predictions can be used for clinical decisions.
Implications:
This study marks one of the first applications of NLP to classify kidney allograft status in Spanish-language EMRs. It opens the door for scalable tools to support clinical review processes, particularly in non-English-speaking countries where tailored AI solutions are lacking.
However, the authors caution that while the models demonstrate strong discrimination and utility, they are not yet ready to replace human judgment. Further refinement, such as improved handling of class imbalance and potential integration with large language models (LLMs), could enhance future performance.
Conclusion:
The use of AI in kidney transplant monitoring shows clear potential but also underscores the ongoing need for human oversight. As models become more sophisticated and inclusive of diverse languages, their role in augmenting—not replacing—clinical care will become increasingly valuable.
About the Author

Leo Silva
Leo Silva is an Air correspondent from Brazil.
Recent Articles
Subscribe to Newsletter
Enter your email address to register to our newsletter subscription!