New AI Architecture 'Engram' Aims to Boost Model Efficiency with Dedicated Knowledge Retrieval
Translate this article
Researchers from DeepSeek-AI and Peking University have introduced a new architectural module for large language models (LLMs) called Engram, detailed in a technical paper published in January 2026. The work proposes "conditional memory" as a new form of sparsity designed to complement the widely used Mixture-of-Experts (MoE) approach.
The research identifies a core inefficiency in current Transformer-based models: they lack a native mechanism for looking up static knowledge, such as common phrases or factual information. Instead, they must dynamically recompute or "reconstruct" this information through multiple neural network layers for each query, consuming computational resources that could be used for deeper reasoning.
How Engram Works
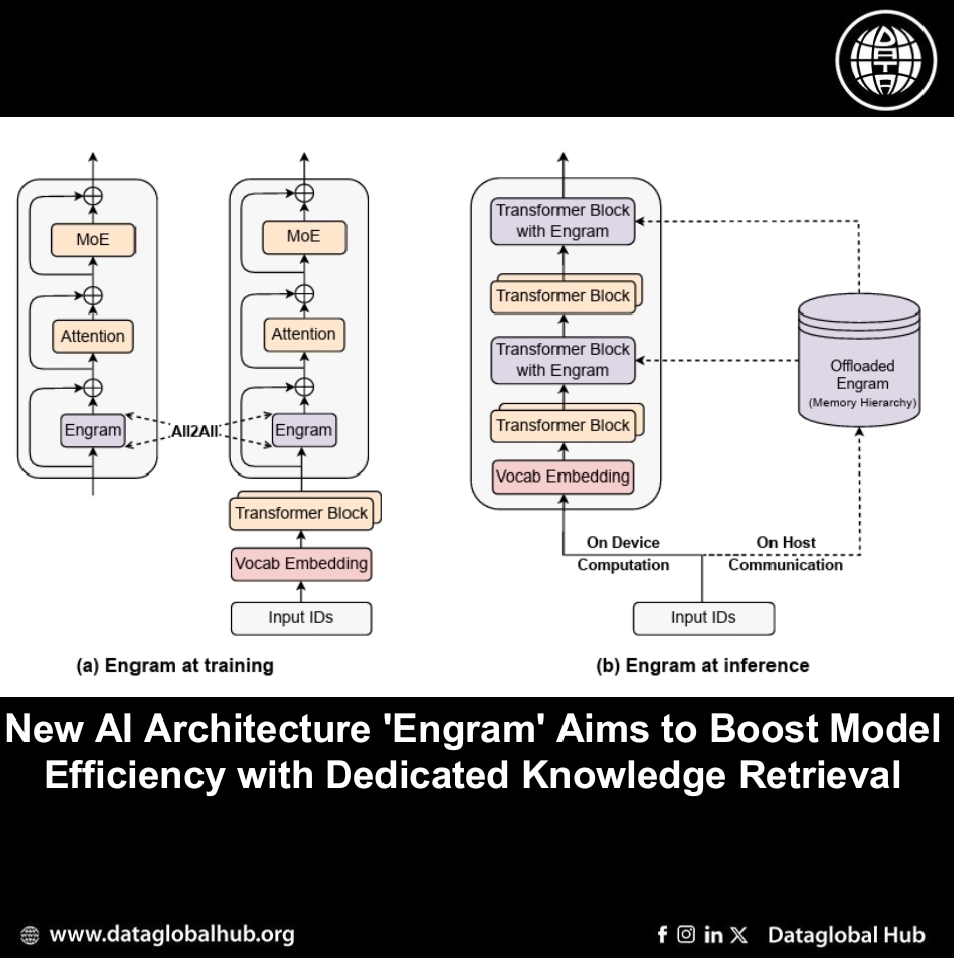
Engram addresses this by acting as a dedicated lookup system within the model. It is based on a modernized version of classic N-gram models—which predict words based on recent context—and uses hashing techniques for efficient, constant-time retrieval of stored information.
The module integrates with a model's existing layers. It takes the current context, retrieves relevant static patterns from a large, specialized embedding table, and then uses a gating mechanism to dynamically blend this retrieved knowledge with the model's ongoing computation. This design allows the model to consult a form of memory without significantly increasing the computational cost per token.
Reported Performance and Synergy with MoE
A central finding of the paper is what the authors term a "U-shaped scaling law" for Sparsity Allocation. This describes the optimal balance between parameters dedicated to MoE experts (for dynamic computation) and those dedicated to the Engram memory (for static lookup). The research indicates that a hybrid model, splitting sparse capacity between both systems, outperforms a pure MoE model with the same total parameter and computational budget.
The team scaled this approach to create Engram-27B, a 27-billion parameter model. According to the paper, it consistently outperformed a strictly comparable MoE-only baseline across a suite of standard benchmarks. Improvements were noted not only in knowledge-intensive tasks (like MMLU and TriviaQA) but also in general reasoning (Big-Bench Hard, ARC-Challenge), reading comprehension (DROP), and coding/mathematics (HumanEval, MATH).
System Efficiency and Long-Context Benefits
The paper highlights two additional advantages:
1. Efficient Scaling: Because Engram's retrieval is deterministic (based on input tokens, not model states), its large memory tables can be efficiently offloaded to host system memory during inference with minimal performance overhead, circumventing GPU memory limits.
2. Enhanced Long-Context Processing: By handling local pattern recognition via lookup, Engram reportedly frees up the model's attention mechanism to focus on longer-range dependencies. The paper states that Engram-based models showed substantially improved performance on long-context retrieval tasks like "Needle-in-a-Haystack."
The research positions Engram as a foundational step toward next-generation sparse model architectures, where conditional memory works alongside conditional computation. The complete code for the project has been released as open source.
About the Author

Noah Kim
Noah Kim is an AI correspondent from South Korea
Recent Articles
Subscribe to Newsletter
Enter your email address to register to our newsletter subscription!