You Still Don't Get It. AI Can Now Work Longer Than You Can Focus
Translate this article
METR, a research nonprofit focused on measuring AI systems' potential for catastrophic harm, has updated its public leaderboard of task-completion time horizons for frontier language models. The latest measurements, published February 20, 2026, include new data for Claude Opus 4.6 and GPT-5.3-Codex.
What a Time Horizon Measures
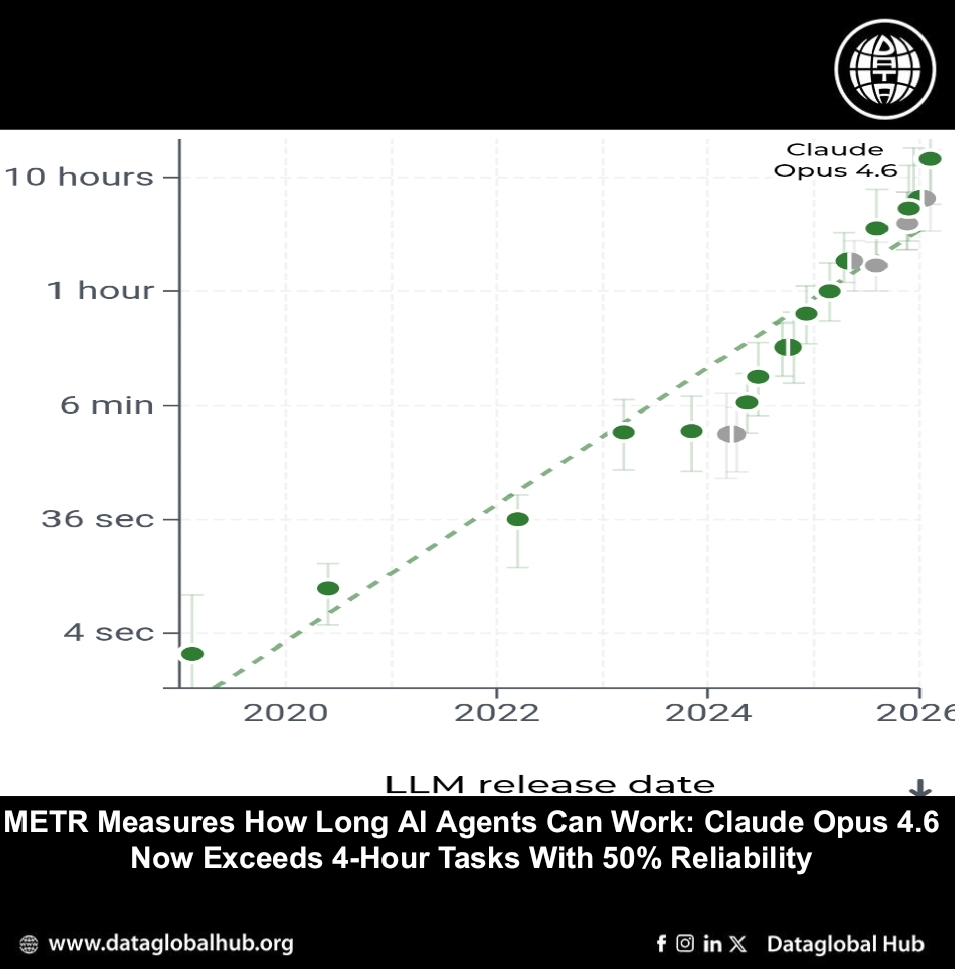
The task-completion time horizon is the duration—measured by human expert completion time—at which an AI agent is predicted to succeed with a given level of reliability. The 50-percent time horizon indicates the task length at which a model succeeds half the time; the 80-percent horizon indicates success four out of five attempts.
These are not measures of how long an AI takes to complete a task—agents are typically several times faster than humans—but of task difficulty. A two-hour time horizon means the model can complete tasks that would take a human expert two hours with 50 percent reliability.
The Latest Numbers
According to METR's measurements, Claude Opus 4.6 now has a 50-percent time horizon exceeding four hours, and an 80-percent time horizon approaching two hours. GPT-5.3-Codex shows similar capability levels. The estimates are derived from performance on over a hundred diverse software tasks drawn from RE-Bench, HCAST, and novel short-task sets.
The data continues an exponential trend observed since 2020. Models released in early 2020 had time horizons measured in seconds; by early 2026, frontier models exceed four hours at 50 percent reliability. METR notes that an exponential curve fits the data significantly better than linear or hyperbolic alternatives, and there is no evidence yet of slowdown.
Methodology Notes
METR's tasks are primarily in software engineering, machine learning, and cybersecurity. They are designed to be self-contained and well-specified, with clear success criteria that can be automatically evaluated. Human baseline times come from skilled contractors—averaging five years of relevant experience, mostly from top-100 universities—who complete tasks with the same instructions and affordances given to AI agents.
The resulting time horizons reflect what a low-context person (like a new hire or freelance contractor) could accomplish, not someone with deep familiarity with an existing codebase or project history.
What It Doesn't Mean
METR is careful to clarify what time horizons do not imply. A two-hour time horizon does not mean an AI can do all intellectual tasks a human can do in two hours—capabilities are uneven across domains, and METR's measurements are specific to software, ML, and cybersecurity tasks.
It also does not mean AI can automate entire jobs. Most real-world work draws on prior context, involves human interaction, and has success metrics that cannot be algorithmically scored. When METR has tested AI on messier, more holistic tasks, performance drops substantially.
Updates and Coverage
The page is updated periodically as new measurements become available. METR notes that capacity constraints mean they cannot evaluate every notable release, and there may be significant gaps between a model's public release and published time-horizon estimates. Recent models without current measurements include Gemini 3.1 Pro, GPT-5.2-Codex, and Grok 4.1.
The full methodology, raw data, and analysis code are available on GitHub.
About the Author

Ryan Chen
Ryan Chan is an AI correspondent from Chain.
Recent Articles
Subscribe to Newsletter
Enter your email address to register to our newsletter subscription!