Ai2 Releases DataDecide: A Benchmark Suite for Smarter Pretraining Dataset Selection
Translate this article
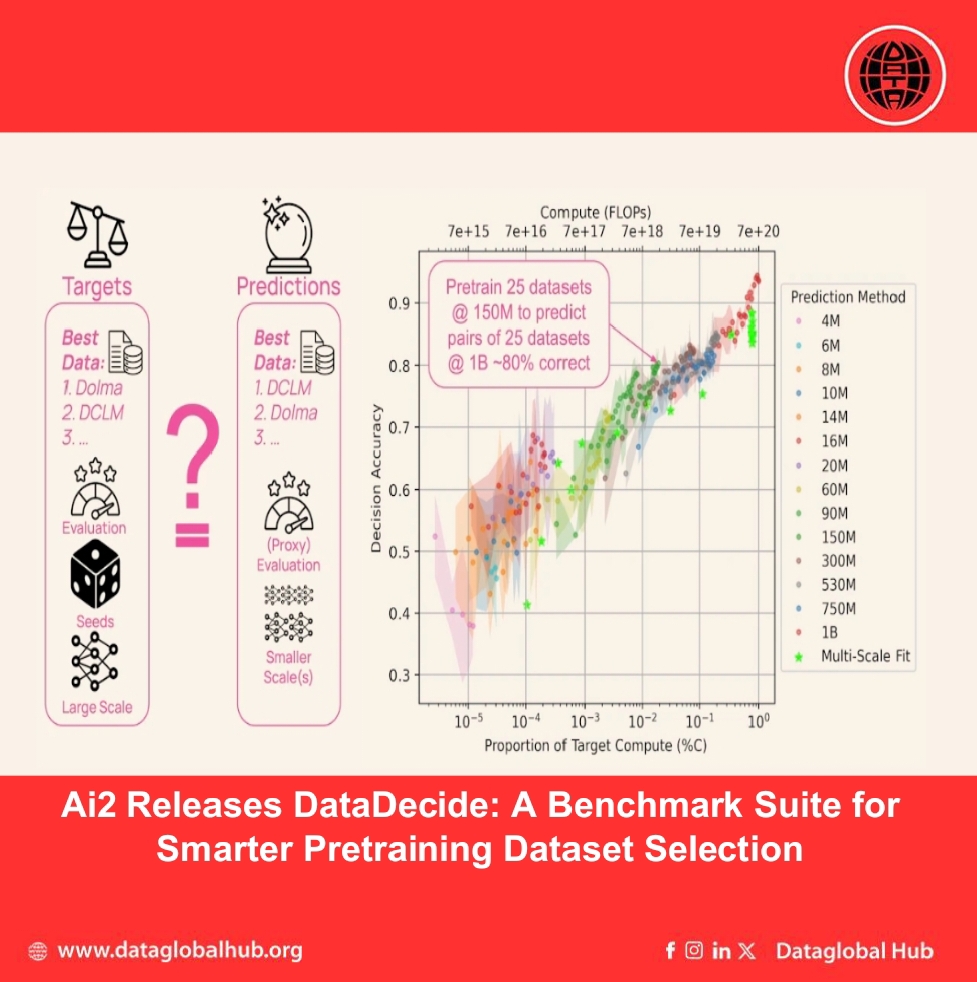
The Allen Institute for AI (Ai2) has introduced DataDecide, a large-scale suite of pretrained models and evaluations aimed at helping AI researchers and developers make informed decisions about pretraining datasets. By openly sharing results from over 30,000 model checkpoints, Ai2 provides a unique resource for understanding how small-scale experiments can predict downstream performance in larger models.
What is DataDecide?
DataDecide consists of language models pretrained on 25 different corpora each with varying sources, levels of deduplication, and filtering spanning up to 100 billion tokens. These models range in size from 4 million to 1 billion parameters, covering 14 sizes in total. Ai2 evaluated each model across 10 multiple-choice downstream tasks to investigate how dataset choices at small scales translate to performance at larger scales.
Key Insights from the Study
What This Means for Developers
Ai2’s findings suggest that developers can make sound pretraining decisions without needing to run full-scale experiments. By selecting more predictable benchmarks (like MMLU or ARC Easy), using character-normalized likelihood for code tasks, and ranking datasets based on a single model size, teams can achieve high decision accuracy while reducing costs.
Why It Matters
Choosing the right pretraining dataset is a critical but resource-intensive step in LLM development. DataDecide shows that well-designed, small-scale experiments can provide strong signals for making larger decisions, helping democratize model development by lowering the barrier to experimentation.
Explore and Extend
DataDecide is publicly available, including models, evaluation data, and code. Researchers are encouraged to build on the work by evaluating additional benchmarks, testing new metrics, or refining prediction strategies.
Check out the full paper and resources here
About the Author

Leo Silva
Leo Silva is an Air correspondent from Brazil.
Recent Articles
Subscribe to Newsletter
Enter your email address to register to our newsletter subscription!