Microsoft's VibeVoice Speech Model Temporarily Disabled After Release
Translate this article
A recently released open-source text-to-speech model from Microsoft, designed for generating long conversational audio, has been temporarily taken down. The model, named VibeVoice, was made unavailable by its developers shortly after its initial publication.
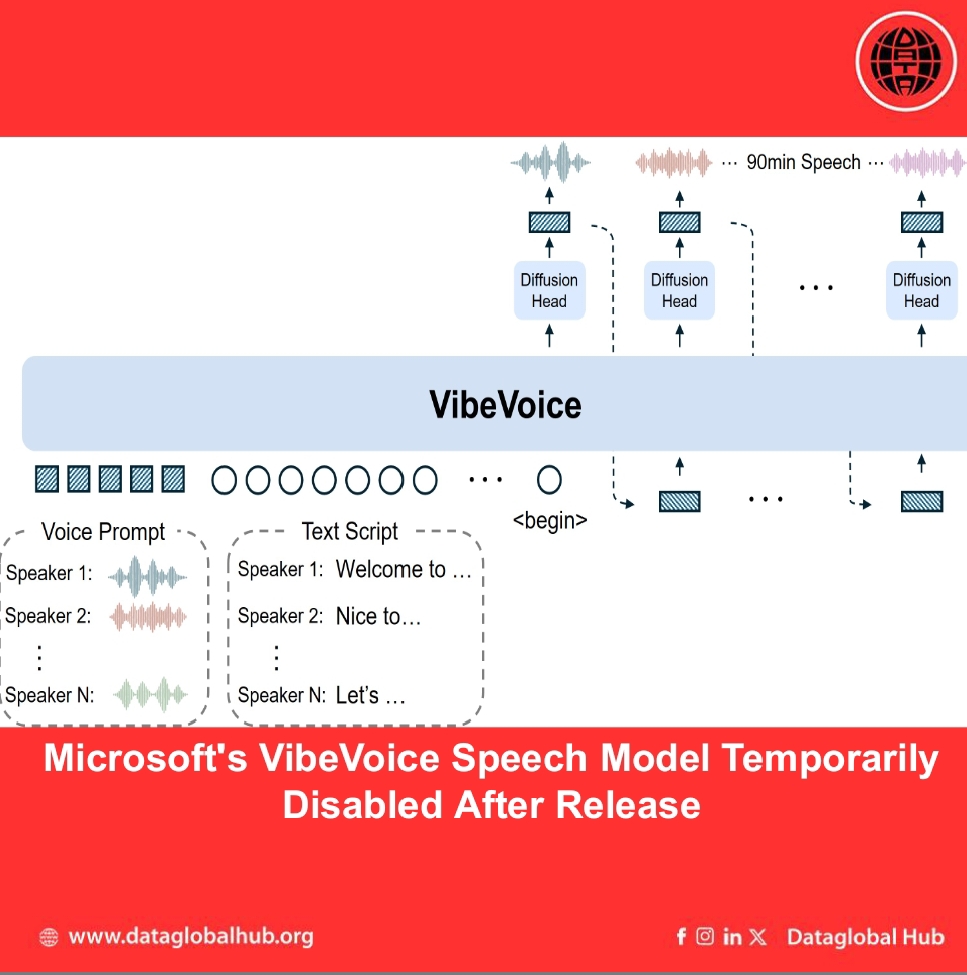
VibeVoice is a framework created to convert text into expressive, multi-speaker audio formats like podcasts. Its design aims to handle challenges in generating longer audio segments, focusing on maintaining consistent speaker voices and managing natural dialogue flow between multiple participants.
Technically, the model utilizes a method involving continuous speech tokenizers that operate at a low frame rate. This approach is intended to maintain audio quality while improving the computational efficiency needed to process extended audio sequences. By combining a large language model to interpret text context with a diffusion component to generate sound, the system can synthesize speech segments as long as 90 minutes with up to four distinct speaker voices. This represents an increase in the number of speakers supported by many existing systems.
The model was released publicly before it was disabled, with the stated goal of encouraging collaboration within the speech synthesis research community. However, the developers subsequently announced the disabling of the project repository.
In a statement, the team noted that after release, they identified instances where the tool was being used in ways that did not align with its intended research purpose. Citing Microsoft's commitment to responsible AI development, they decided to disable access to the model. The repository will remain offline until the developers can implement measures to prevent misuse.
The situation highlights the ongoing balance in the AI community between open collaboration and the need to safeguard against potential misuse of powerful generative tools. The developers indicated the takedown is a temporary measure, pending further review.
Read more about the model:
About the Author

Noah Kim
Noah Kim is an AI correspondent from South Korea
Recent Articles
Subscribe to Newsletter
Enter your email address to register to our newsletter subscription!