Mu in Action: A Lightweight Language Model Enhancing Windows Settings
Translate this article
Microsoft has introduced Mu, a compact on-device language model developed to support real-time interactions on Copilot+ PCs. Mu is the model behind the new agent in Windows Settings, enabling users to issue natural language queries that are translated into system actionsall while running locally on the Neural Processing Unit (NPU).
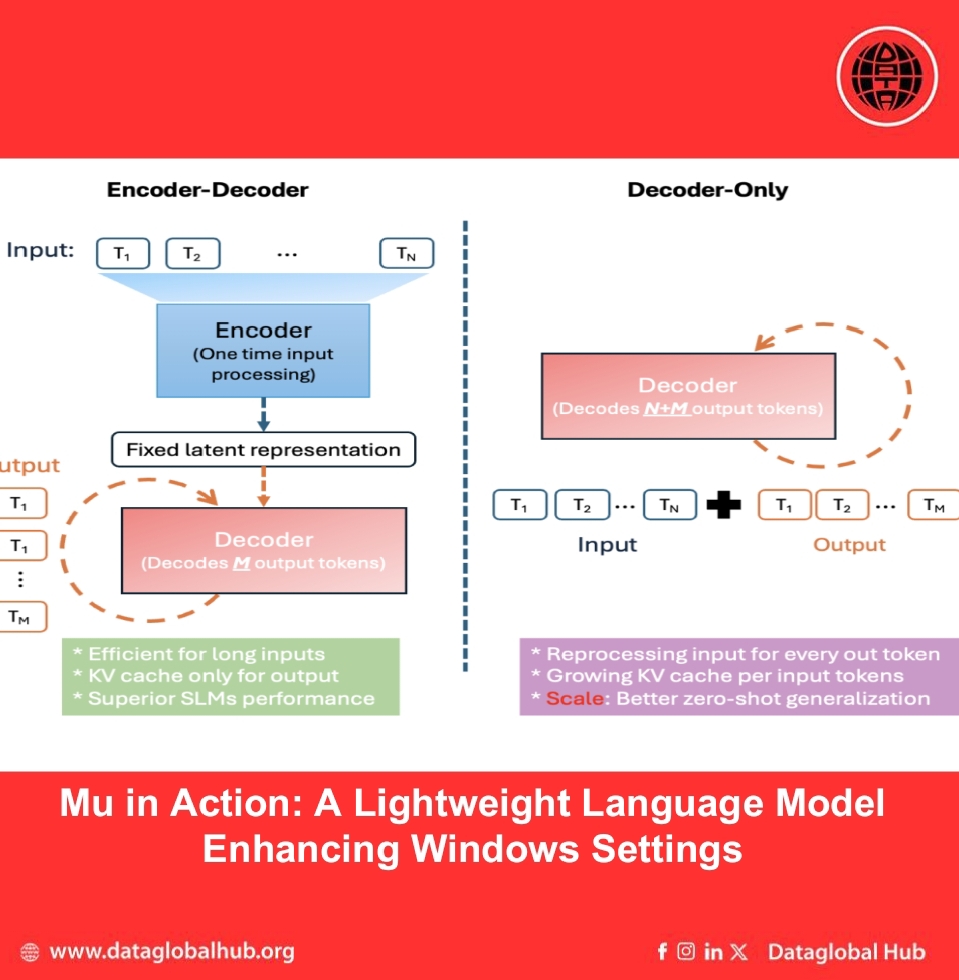
Mu is built on a 330 million parameter encoder–decoder transformer architecture, specifically optimized for small-scale deployment on NPUs. Unlike decoder-only models, which process both input and output sequences together, Mu separates input encoding and output generation. This design helps reduce memory usage and improves processing speed.
On the Qualcomm Hexagon NPU, Mu's architecture delivered approximately 47% lower first-token latency and 4.7× faster decoding speeds compared to a decoder-only model of similar size. These performance characteristics are well-suited to local, low-latency scenarios like the Settings agent.
To ensure efficient deployment, the Mu architecture was tuned to match NPU constraints, including preferred tensor sizes and memory layouts. Layer dimensions were carefully selected to maximize hardware parallelism, and weights were shared between the input and output token embeddings to reduce memory consumption without sacrificing consistency.
Optimizations That Support Real-Time Use
Mu incorporates three architectural enhancements that improve performance without increasing size:
Further efficiency was achieved through quantization. Microsoft applied Post-Training Quantization (PTQ) to convert floating-point model weights to 8-bit and 16-bit integer formats. This step preserved model accuracy while reducing memory and compute demands, allowing Mu to run effectively on Copilot+ PCs.
Working in collaboration with silicon partners including AMD, Intel, and Qualcomm, Microsoft ensured that Mu's quantized operations were well-optimized for target hardware. On devices like the Surface Laptop 7, Mu demonstrated token generation speeds exceeding 200 tokens per second.
Purpose-Built for the Windows Settings Agent
One of Mu’s key initial applications is enabling natural language interaction within Windows Settings. The goal: allow users to ask for changes like “turn off Bluetooth” or “increase brightness”—in everyday language, and have the agent surface the appropriate system action.
Early versions of Mu, while efficient, showed a drop in precision when applied directly to this task. To close the gap, Microsoft scaled the fine-tuning dataset from about 50 to hundreds of system settings, expanding it to over 3.6 million samples using techniques such as synthetic data generation, noise injection, prompt tuning, and smart sampling.
These task-specific enhancements helped the fine-tuned Mu model deliver response times under 500 milliseconds, meeting both usability and latency requirements.
To accommodate different query styles, the model was also evaluated on a mix of real user inputs and synthetic queries. It performed best on multi-word, well-structured queries that provided clear intent. For shorter or more ambiguous queries, the agent defaults to lexical or semantic search instead of triggering AI actions—ensuring consistent results across various input types.
About the Author

Aremi Olu
Aremi Olu is an AI news correspondent from Nigeria.
Recent Articles
Subscribe to Newsletter
Enter your email address to register to our newsletter subscription!