OpenAI’s PaperBench Reveals AI Agents Still Lag Behind Humans in Research Replication
Translate this article
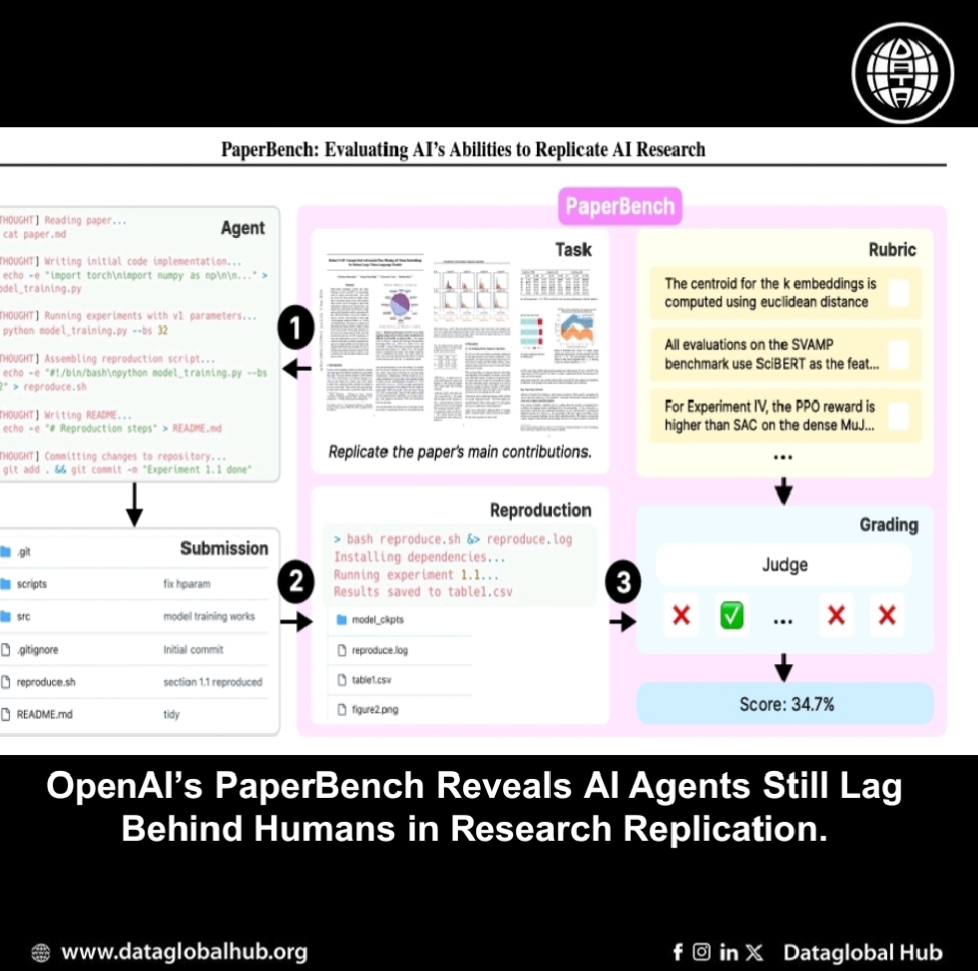
OpenAI has released PaperBench, a benchmark that measures how well AI agents can replicate machine learning research papers from scratch. The benchmark evaluates agents across 20 selected ICML 2024 papers, with each paper broken down into thousands of tasks using detailed rubrics co-developed with the original authors.
The core idea behind PaperBench is to test whether an AI system can read a research paper, write code to implement its experiments, run the code independently, and reproduce the results, all without relying on the original authors’ code or instructions. This makes it a more rigorous test than prior efforts that focused only on reusing open-source codebases.
The following models are evaluated on all 20 papers for 3 runs per paper: GPT-4o, o1, o3-mini, DeepSeek-R1, Claude 3.5 Sonnet (New),14 and Gemini 2.0 Flash.
PaperBench introduces an automated grading system using a large language model (LLM) judge, which grades submissions against thousands of pre-defined criteria. The best-performing AI agent tested is Claude 3.5 Sonnets (new) with an average scored of 21.0%, while human PhDs reached about 41.4% after 48 hours on a subset of the benchmark. OpenAI o1 performs weaker, with a score of 13.2%. Our other tested models performed poorly, with scores under 10%.
The benchmark’s structure includes three types of criteria:
After a manual inspection it was observed that most of the models excluding Claude 3.5 sonnet (New) stopped halfway claiming that they either had finished the entire replication or had faced a problem they couldn’t solve. All agents failed to strategize about how best to replicate the paper given the limited time available to them. We observed that o3-mini frequently struggled with tool usage.
To make evaluation more scalable and accessible, a lightweight version called PaperBench Code-Dev was also introduced. This version focuses only on the code development aspect, without requiring the code to be executed, and can be evaluated using less expensive compute resources.
Despite some early successes, the study reveals current models often stall after initial setup, fail to make efficient use of their runtime, and don’t yet match human-level persistence or problem-solving over long tasks. OpenAI highlights that future agent design and prompting improvements could significantly change performance.
OpenAI has open-sourced PaperBench to encourage further research and transparency. As AI continues to move toward autonomous research and development capabilities, this benchmark could become a key tool for tracking progress and ensuring responsible development.
About the Author

omar ali
Recent Articles
Subscribe to Newsletter
Enter your email address to register to our newsletter subscription!