VaultGemma: A New Benchmark for Privacy-Focused AI
Translate this article
The team behind Gemma has introduced VaultGemma, described as the largest open large language model (LLM) trained from scratch with differential privacy (DP). With 1 billion parameters, VaultGemma is designed to balance capability with rigorous privacy guarantees, addressing one of the most pressing challenges in AI development.
Why Differential Privacy Matters
As AI becomes more embedded in daily life, ensuring that models protect sensitive data is a critical concern. Differential privacy offers a mathematically sound approach by adding calibrated noise during training to prevent memorization of specific examples. However, this introduces trade-offs: DP reduces training stability, increases computational costs, and changes the scaling rules that typically guide LLM performance.
To address these issues, the team in partnership with Google DeepMind conducted research titled “Scaling Laws for Differentially Private Language Models.” This work establishes scaling laws that help predict and manage the compute-privacy-utility trade-offs in DP training.
Establishing Scaling Laws
The researchers showed that model performance under DP is largely governed by the noise-batch ratio the balance between added privacy noise and training batch size. Through extensive experiments across different model sizes and configurations, they built formulas to estimate training loss under given compute, privacy, and data budgets.
Key insight: DP training often benefits from smaller models trained with much larger batch sizes than conventional approaches.
Building VaultGemma
Using these scaling laws as a guide, the team trained VaultGemma, a 1B-parameter model based on the Gemma 2 architecture. Training leveraged Scalable DP-SGD to handle Poisson sampling while keeping batch sizes consistent, maintaining both strong privacy protections and training efficiency.
VaultGemma was trained with a sequence-level DP guarantee of (ε ≤ 2.0, δ ≤ 1.1e-10), applied across sequences of 1024 tokens. This means individual training sequences exert minimal influence on the final model, reducing the risk of memorization. Testing confirmed that VaultGemma shows no detectable reproduction of training data.
Performance and Comparisons
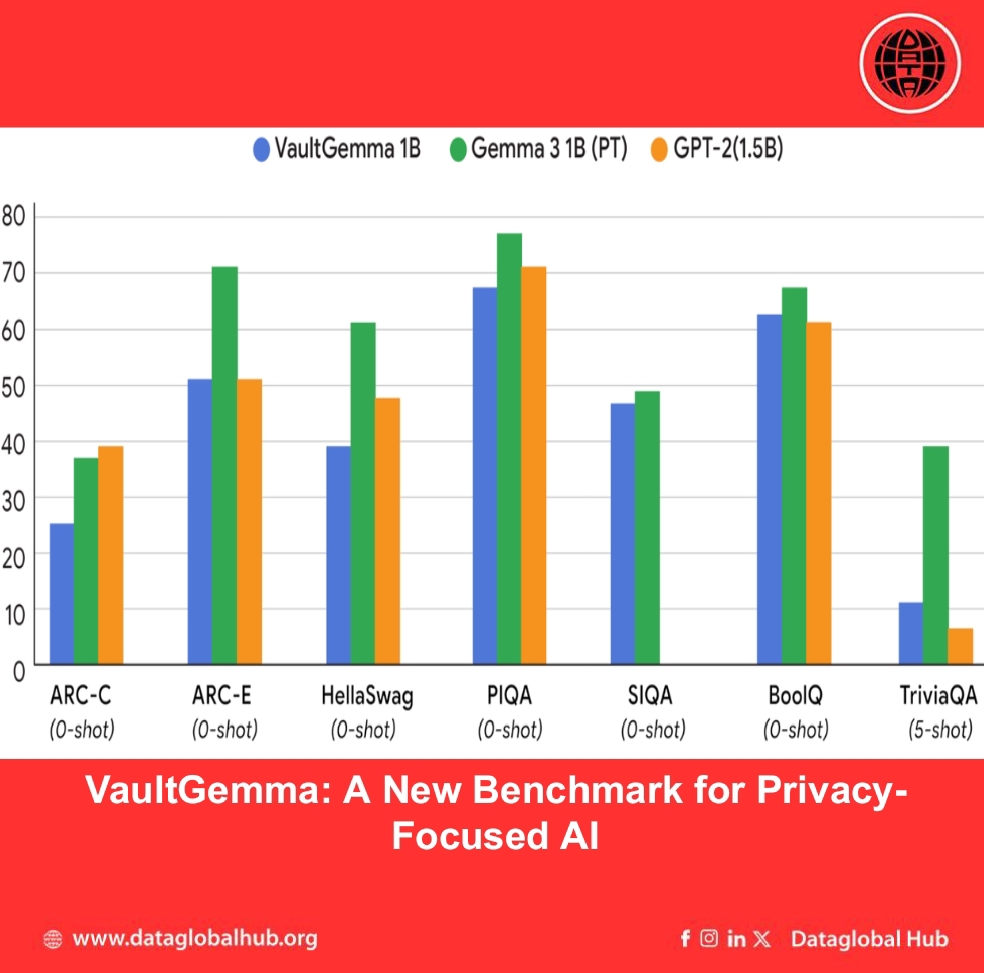
On standard academic benchmarks (HellaSwag, BoolQ, PIQA, SocialIQA, TriviaQA, ARC-C, ARC-E), VaultGemma performed comparably to older non-private models such as GPT-2 (1.5B), while showing the resource costs still involved in matching the performance of recent non-DP models.
The results confirm that DP-trained models can now achieve utility on par with mainstream non-DP models from approximately five years ago — a gap that ongoing research aims to narrow.
Availability
VaultGemma’s weights are available on Hugging Face and Kaggle, accompanied by a technical report. The release is intended to provide the AI community with both a usable model and a reference framework for future research on private model training.
Looking Ahead
VaultGemma marks a step toward AI systems that are powerful yet private by design. While challenges remain, especially in closing the performance gap with state-of-the-art non-private models, this release provides a roadmap and toolset for building safer and more responsible AI.
About the Author

Jack Carter
Jack Carter is an AI Correspondent from United States of America.
Recent Articles
Subscribe to Newsletter
Enter your email address to register to our newsletter subscription!