MiniMax-M1: Advancing AI Reasoning with Efficiency and Versatility
Translate this article
MiniMax-M1, developed by MiniMax, is an open-weight, large-scale language model that combines a hybrid-attention architecture with robust reasoning capabilities. Designed for tasks requiring deep analysis and long-context processing, it offers a compelling option for developers and researchers. Here’s a closer look at what MiniMax-M1 brings to the table, its strengths, and areas to consider when using it.
A Hybrid Architecture for Efficiency
MiniMax-M1 leverages a Mixture-of-Experts (MoE) framework paired with a lightning attention mechanism, enabling it to handle up to 1 million tokens, eight times the context length of DeepSeek R1. With 456 billion parameters, of which 45.9 billion are activated per token, the model achieves notable efficiency, using 25% of the FLOPs required by DeepSeek R1 at a 100,000-token generation length. This makes it well-suited for complex tasks like software engineering and long-document analysis.
Available in two variants: MiniMax-M1-40K and MiniMax-M1-80K, with different thinking budgets, the model caters to varying computational needs. The 80K version is designed for more intensive tasks, though benchmark results occasionally show the 40K model performing comparably, likely due to task-specific optimizations not fully detailed in the documentation.
Benchmark Performance: Strengths and Context
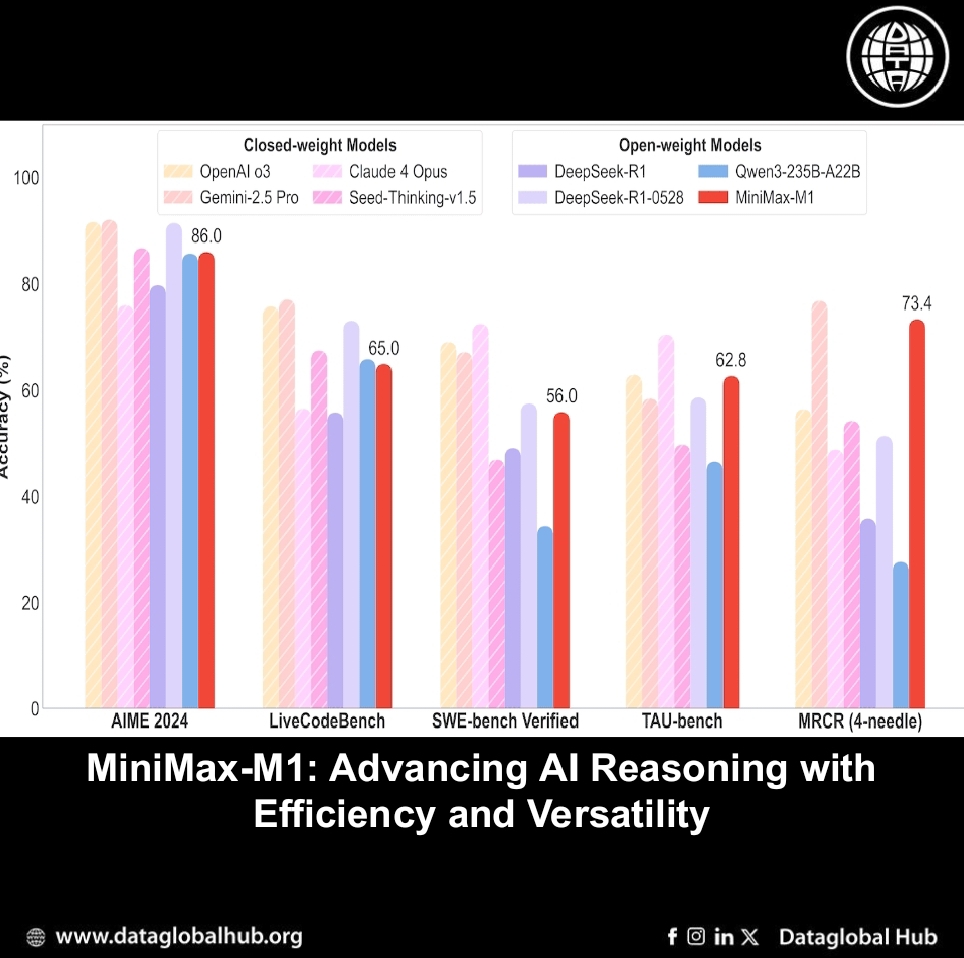
MiniMax-M1 has been evaluated across diverse benchmarks, showing competitive performance. On AIME 2024 and 2025, it scores 86.0 and 76.9, respectively, trailing commercial models like Gemini 2.5 Pro (92.0 and 88.0) but outperforming some open-weight peers like DeepSeek R1 (79.8 and 70.0). In coding, it achieves 65.0 on LiveCodeBench and 68.3 on FullStackBench, demonstrating practical utility. For software engineering, MiniMax-M1-80K scores 56.0 on SWE-bench Verified, tested on 486 of 500 tasks due to infrastructure incompatibilities with 14 cases (e.g., astropy__astropy-7606).
The model excels in long-context tasks, scoring 73.4 on OpenAI-MRCR (128k) and 56.2 on OpenAI-MRCR (1M), alongside 61.5 on LongBench-v2. For agentic tool use, it delivers 62.0 (airline) and 63.5 (retail) on TAU-bench. However, it underperforms on tasks like HLE (8.4) and SimpleQA (18.5), indicating limitations in specific reasoning and factuality scenarios compared to models like Claude 4 Opus (10.7 and unavailable).
Training with CISPO: A Novel Approach
MiniMax-M1’s training leverages a reinforcement learning (RL) framework with CISPO (Clipped Importance Sampling Policy Optimization), which clips importance sampling weights for stable learning. This, combined with the hybrid-attention design, enhances training efficiency across diverse tasks, from mathematical reasoning to software engineering sandboxes. While effective, the lack of detailed training data specifics (e.g., dataset composition) limits full transparency about its learning process.
Why MiniMax-M1 Stands Out
MiniMax-M1 is a versatile tool for tackling complex, long-context tasks, from coding to reasoning. Its open-weight nature (Apache-2.0 license), accessible via Hugging Face and GitHub, encourages experimentation. While not without limitations, its efficiency and benchmark performance make it a strong contender for developers and researchers. For more details, check the technical report or contact model@minimax.io. https://github.com/MiniMax-AI/MiniMax-M1?utm_source=alphasignal
MiniMax-M1 isn’t a one-size-fits-all solution, but it’s a thoughtful addition to the AI landscape, ready to support those diving into intricate challenges with a blend of power and practicality.
About the Author

Leo Silva
Leo Silva is an Air correspondent from Brazil.
Recent Articles
Subscribe to Newsletter
Enter your email address to register to our newsletter subscription!