Reasoning Efficiency Refined: Tencent Unveils Hunyuan-T1:The First Mamba-Powered Ultra-Large Model.
Translate this article
Tencent has officially released the in-depth thinking model of the Hunyuan large model series called "Hunyuan-T1". This model is based on the world's first ultra-large-scale Hybrid-Transformer-Mamba MoE large model: "The TurboS fast-thinking base." Hunyuan-T1 marks a significant evolution from the previously released T1-preview model on the Tencent Yuanbao APP, its reasoning ability has been significantly expanded and it now further aligned with human preferences through large-scale post-training.
A standout feature of Hunyuan-T1 is its optimization for long-text reasoning. The model leverages TurboS’s advanced context retention capabilities to mitigate challenges like context loss and long-distance dependency. Meanwhile, the Mamba architecture enhances long-sequence processing while reducing resource consumption, delivering 2x decoding speed under identical deployment conditions compared to earlier iterations.
A major part of the model's progress stems from an intensive reinforcement learning phase, during which 96.7% of total computing power was allocated to improving pure reasoning ability and alignment. The training strategy incorporated curriculum learning, gradually increasing data complexity while expanding context length to help the model utilize tokens more efficiently.
The team sourced a diverse dataset encompassing mathematics, logic, scientific reasoning, and coding, spanning from basic problem-solving to domain-specific, PhD-level challenges. Reinforcement learning techniques like data replay and periodic policy resetting were used to enhance training stability by over 50%. In the alignment stage, a unified reward feedback system combining self-reward scoring and guided reinforcement helped the model learn to refine its own outputs with more detailed and efficient responses.
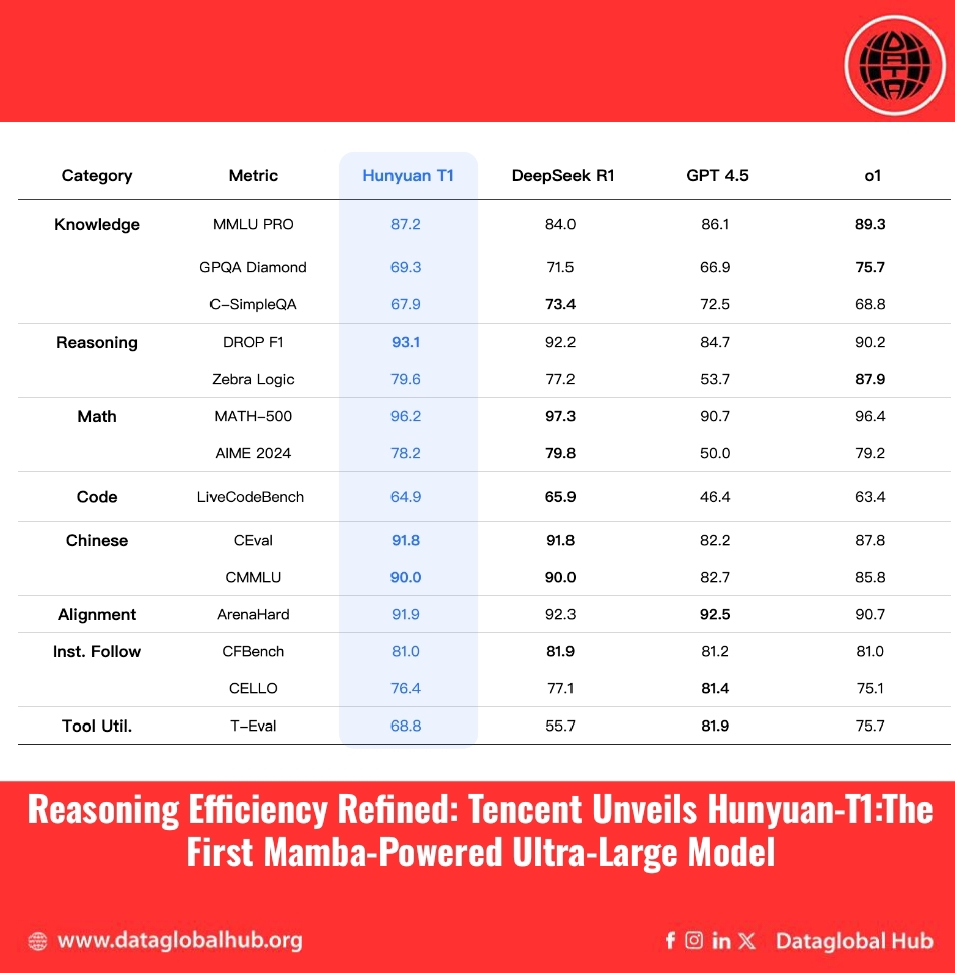
Benchmark Performance
Hunyuan-T1 delivers competitive results across a broad spectrum of benchmarks:
These results show that Hunyuan-T1 performs comparably to leading models like DeepSeek R1 across several public benchmarks and internal evaluations. In areas like creative instruction following, summarization, and agent-based tasks, it even exhibits a slight advantage.
Hunyuan-T1 sets a new benchmark for language models that prioritize reasoning over just raw fluency, offering promising potential across scientific research, education, programming, and AI-assisted decision-making.
As the ecosystem evolves, Hunyuan-T1’s core strengths fast decoding, efficient long-sequence processing, and reliable multi-domain reasoning:position it as a compelling alternative in the era of advanced general-purpose language models.
About the Author

Chinedu Chimamora
Recent Articles
Subscribe to Newsletter
Enter your email address to register to our newsletter subscription!